Herbert W. Armstrong Searchable Library
Notes on Searchability
scroll down
PDF Best Practices #5: Acrobat's Find & Search
Text retrieval functionality is key with
'digital haystacks' of information
19 April 2002
By Shlomo Perets
of MicroType
(www.microtype.com)
Some documents,
publications or books are read from beginning to end and are never opened
again; others are read partially or only browsed, and then referred to again
when looking for more information on a specific item. Electronic documentation
is the ideal format for this "reference" mode, as in addition to the
traditional table of contents and indexes and their online implementations, it
supports search functions to efficiently locate all instances of required
items.
Text retrieval functions
make the difference between a digital haystack where items are "known to
exist somewhere" but nevertheless cannot be located without a significant
effort, and a document collection where required items can be found instantly
even when there are thousands of pages in multiple files.
Acrobat offers two text
retrieval functions that differ in concept and implementation: the basic Find
function, and the more advanced Search function. The differences between these
functions will be discussed in detail later in this column.
What You
See Is Not Necessarily There
Both Find and Search
suffer from a number of problems related to text representation. For both
functions to work, text in the electronic document must be identical to the
text in the original document. This may seem obvious, but many insidious
side-effects are introduced when a document is converted to PDF, and often even
the PDF producer, let alone the reader, is unaware of the implications this has
on text retrieval.
Correct text
representation, however, should not be taken for granted, as there are still
several issues which will cause text not be to searchable consistently:
·
Older
drivers, ATM versions and printer driver settings can cause text in some fonts
to be "garbled" internally (it prints and displays as intended, but it
is not searchable).
- Pre-Acrobat 5 font issues for producers/readers using
older versions, which cause text to be distorted.
- Ligatures (with a few exceptions), small caps and
old-style numerals are not searchable in Acrobat.
- Acrobat may interpret visual white space between
letters as additional space characters. With some fonts, this may happen
even when standard spacing is used. In other cases, spaces between words
may be ignored with smaller-size text.
- Sometimes larger characters may be converted to
bitmaps in the production process (driver-dependent).
- Type 3 fonts (either used in the original document or
fonts transformed to Type 3 during the PDF production), may not be
searchable.
It is also worthwhile
noting that documents scanned into PDF are not searchable. Scanned PDFs to
which optical character recognition (OCR) was applied may be partially
searchable, but with a significant numbers of errors -- with words not found or
mis-recognized.
Leaving these issues
aside, one has to remember that PDF is essentially a presentation format and
not a document in the sense of text flow. Searches will not work when the
phrase being searched for is split between pages. Depending on the applications
used to author and create the PDF, there may be additional problems of lines
placed in a reversed or unexpected order, so that phrases split across lines
are not located. Items split between lines in table cells or in multi-column
layouts may also be impossible to locate (as the word sequence uses a logic
different from what is expected). Hyphenated words or phrases with natural
hyphens split between lines may also pose difficulties, depending on the
specific authoring applications or PDF creators. When creating "Tagged
PDFs" (authored with Word2000 + PDFMaker 5 or FrameMaker 7.0), the
additional information stored in the PDF file significantly improves
Find/Search functionality. "Structured PDFs" (as authored with Word98
+ PDFMaker or FrameMaker 6.0) make no difference with respect to text searches,
despite the extra structure information embedded in the PDF.
Find
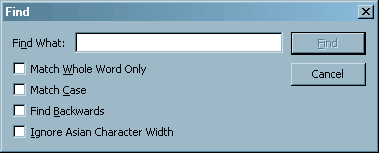
![]() The Find function (Edit > Find) does not require
special preparations on the part of the PDF producer, other than verifying that
text is interpreted correctly in Acrobat. Find locates the specified text (word
or phrase) in the currently open PDF file only (locally or in a web browser);
options include matching letter case and "whole word".
The Find function (Edit > Find) does not require
special preparations on the part of the PDF producer, other than verifying that
text is interpreted correctly in Acrobat. Find locates the specified text (word
or phrase) in the currently open PDF file only (locally or in a web browser);
options include matching letter case and "whole word".
In terms of speed, the
Find function is rather slow, even with the fastest computers. (Try locating a
phrase, which is present in one of the last pages in a PDF file containing a
few hundred pages, and you'll see the status bar showing the page numbers
rolling page by page).
Search
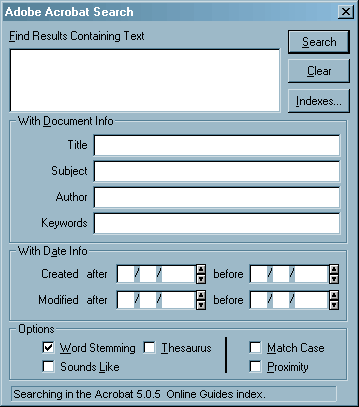
![]() Compared to Find, the Search function (Edit >
Search > Query) is much more efficient. Search supports powerful text
retrieval functions such as looking for multiple words, together with logical
operators (And, Not, Or), with optional Proximity (locating multiple items only
if they are in approximately the same three-page zone, or a larger zone if
there is not much text per page), as well as word stemming, "sounds
like", thesaurus and wildcards options.
Compared to Find, the Search function (Edit >
Search > Query) is much more efficient. Search supports powerful text
retrieval functions such as looking for multiple words, together with logical
operators (And, Not, Or), with optional Proximity (locating multiple items only
if they are in approximately the same three-page zone, or a larger zone if
there is not much text per page), as well as word stemming, "sounds
like", thesaurus and wildcards options.
The Search function can
also use PDF metadata, i.e. file-specific DocInfo fields such as Title,
Keywords, Author, Subject (and optionally custom fields). When including these
fields in the search query, fields and their value range can either be typed
directly, or can be added to the Search dialog box (Preferences, Search,
Include in Query); custom fields can only be typed directly. It is possible to
search based on field values exclusive, or to combine phrases with field
values.
Search is cross-document
and very fast compared to the Find function -- both factors are related to the
mechanics of the Search function: the PDF producer uses Acrobat Catalog in
advance to prepare a "full-text search index", listing all words in
the document collection being indexed. This "index" (.pdx file
pointing to a folder structure with index-specific files) provides the Search
function with pointers to all occurrences of different words (including text in
vector graphics, if it is retained as text). When the user searches for a word,
it is the pre-prepared index that is being searched, and not the document
itself. When a word is found, pointers to the locations in documents within the
collection are displayed. This means that the user in not searching within the
current document, and can search for a word without any documents being open.
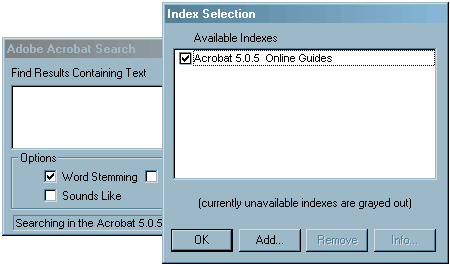
With the Search function,
the user must first select/activate the index [shown above] to be used (Edit
> Search > Select Indexes, or the Indexes button in the Search dialog
box). The PDF producer should assist, whenever possible, by associating the
index with PDFs in the document collection -- either with PDFs that are
considered main entry points, or with all PDFs. This way, end-users will
automatically have the index activated without having to select it manually. An
exception to this is when the same PDFs are distributed individually or placed
on a site; Acrobat will display an error message if the attached index is not
present. (Acrobat Search requires the index and all PDFs to be stored on a
local or network drive, maintaining the relative path present when the index
was created. Search won't work if the index or PDF files are stored in a web
site; there are, however, third-party products that support PDF searches on the
web).
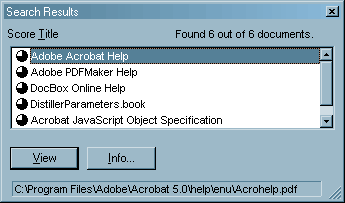 The Search function typically searches a group of
documents; when it displays the search results, this is comprised of a list of
all matching PDF files, each shown by its title and a score. Clicking any of
the titles takes you to the first page with corresponding hits in that file,
highlighted. Clicking the Previous Highlight or Next Highlight buttons takes
you to the previous or next occurrence, moving transparently to the next or
previous file in the list of results. The search results can be narrowed down
by searching within the Search Results, rather than searching the entire
collection again (hold down the Control or Option keys, and the Search button
changes to Refine).
The Search function typically searches a group of
documents; when it displays the search results, this is comprised of a list of
all matching PDF files, each shown by its title and a score. Clicking any of
the titles takes you to the first page with corresponding hits in that file,
highlighted. Clicking the Previous Highlight or Next Highlight buttons takes
you to the previous or next occurrence, moving transparently to the next or
previous file in the list of results. The search results can be narrowed down
by searching within the Search Results, rather than searching the entire
collection again (hold down the Control or Option keys, and the Search button
changes to Refine).
If there is only one hit,
Acrobat takes you directly to the location in which hits are found --
highlighting the matching words (without displaying the Search Results box with
document titles).
Having a meaningful PDF
document title is essential, as the file name -- displayed instead of a title
-- is not descriptive or "friendly" enough. It is also a good idea to
set the opening mode of all files to show the title in the title bar to
maintain orientation as to the item currently being viewed, so that it will be
of use even if the document is opened at the middle of file, as can often
happen when clicking the Next/Previous Highlight buttons (or, for that matter,
when following cross-file links or bookmarks). In Acrobat 5, select File >
Document Properties > Open Options, "Display Document Title"; when
the PDF is displayed with previous versions of Acrobat, select "Resize
Window to Initial Page" for a similar effect.
To take advantage of the
Search function and display the list of results so that the specific section of
interest can be selected directly, it is essential that the PDF document or
document collection is constructed as a set of independent chapters, each being
a separate PDF, and not as book/s converted to single-file PDFs. Each PDF
should have its own unique Title, Subject, Author and Keywords fields --
chapter-specific -- applied consistently throughout the document collection;
these also help to pinpoint subjects of interest.
When searching a
single-file book with the Search function, the reader has to click the Next
Highlight button continuously, with no clues as to the location/context
(similar to the situation when using Find), meaning that readers back in the in
the digital haystack.
When the same source
material is split into multiple files and the Search function is used, the list
of results indicates the probable sections, so that the reader can decide,
based on the title, whether to click the document. Having separate chapters
also means that it is possible to open multiple windows if necessary, each with
its own title displayed in the title bar. (Splitting a book to separate
chapters should not compromise navigation -- this is possible through the use
of cross-file links and bookmarks.)
It is recommended to
provide a meaningful title for the index, and also include a brief description
(including information as to options enabled or disabled for the index).
Even when all groundwork
for powerful and efficient searches is there, readers can be helped in various
ways:
·
First
and foremost, "Reader with Search" should be indicated as a required
version (free download; the Search function is not available in the somewhat
smaller-size Reader).
- A Search button or bookmark can make the function
more visible to readers who are not aware of the difference between Find
and Search.
- A brief "How To" section, explaining how to
use the Search function, with screen captures showing sample queries
related to the topics in the document collection. Such a section -- which
may be only 3 or 4 pages long -- is not meant to replace the corresponding
items in Acrobat online help, but rather to provide a quick guide to
getting results, in a way that is optimized for the specific document
collection. Such a "How To" section could be bookmarked under
the Search bookmark.
- If applicable, add a "Common Queries"
bookmark, under which queries likely to be used more often by readers are
listed. Clicking each of these items runs the pre-defined query and
results are instantly displayed (using a simple JavaScript function new in
Acrobat 5).
- The index should be activated automatically when
opening the PDF. For advanced applications where multiple indexes are used
concurrently, it is possible to deselect active indexes as well.
Searching for specific
information does not exclude other access/navigation mechanisms, including
bookmarks and links in items such as a table of contents or a standard index;
these complement one another. Whereas the table of contents and index lists
items directly so that they can be selected, one has to know precisely what to
look for when using Find or Search.
PDFs in
Acrobat 5 CD
Large
Single-File PDFs
The major shortcoming of
the Acrobat 5 PDFs, in my opinion, is the inefficient use of the Search
function. Acrobat Help (page 222) rightly advises: "Consider creating a
separate PDF file for each chapter or section of a document. When you separate
a document into parts and then search it, search performance is
optimized." However, all PDFs in the Acrobat 5 CD were constructed as a
single PDF for an entire book. This applies to the Acrobat Help itself, but
also to the PDF Reference (696 pages) and even to the gigantic Acrobat Core API
Reference (2755 pages). When searching for "event", for example, we
get 16 books listed, with no clues as to specific sections within these books
where items are located. (It is possible to formulate the search query for a
better focus and fewer items listed, but the end result is still entries that
show the entire book.)
The Core API Reference
demonstrates another potential problem, where Acrobat Catalog splits very large
PDFs to two or more parts. In the Search Results, we see two entries which
relate to the same PDF: "Acrobat Core API Reference" and
"Acrobat Core API Reference: Pages 2389 to 2755." While it may be
possible to minimize this separation by modifying Catalog preferences, it is
best to avoid having such large PDFs in the first place.
Text
Representation Problems
Text in PDFs in the
Acrobat 5.0 CD is generally "well-behaved" -- no major anomalies are
found.
In a few documents,
spaces are missing in the "internal representation". As an example,
inspect the Contents page in the Acrobat Development Overview
(DevelopmentOverview.pdf in the Getting_Started folder in the SDK
documentation). When trying to locate the phrase "This Document",
which appears three times in the top area of the page, you will not succeed.
Select the text with the Text Select Tool, copy and paste it to a text editor;
you will then be able to see that spaces are missing in different locations:
- IntroductionToThisDocument
- HowThisDocument IsOrganized
- RelatedDocumentation
- ConventionsUsedInThisDocument
Trying to find
"ThisDocument" will succeed in locating these instances. A similar
problem can be seen in the "Acrobat Developer FAQ" PDF.
Extra spaces added in
random locations within words are actually a more common problem in PDFs, but
in the case of the Acrobat 5 PDFs this was not traced.
The Acrobat Help file
(Help > Acrobat Help) demonstrates the problem associated with hyphenation.
The document uses moderate hyphenation, where only longer words are hyphenated,
with 5 or more characters left on either side. These hyphens -- such as in
"accessi-bility", "appli-cation" -- cause text to be
interpreted differently. Searching for plain "accessibility" and
"application" will not locate the hyphenated versions, but "accessi
bility" and "appli cation" (with a hyphen or spaces in the
hyphen's location) will succeed.
The opposite problem --
of a hyphen discarded at end of line -- is seen in the Acrobat JavaScript PDF
(Help > Acrobat JavaScript Guide). Trying to find "client-side"
(typing either "client-side" or "client side"), we get one
match. But is it the only instance? No. Using Find with "clientside"
we locate another instance where "client-side" is split between lines
at the "natural" hyphen.
The Acrobat Distiller
Parameters (DistillerParameters.pdf in PDF_Creation_APIs) demonstrates the
impact of having information arranged in tabular form, with multi-line items.
Acrobat has no idea of the presence of table columns, which significantly
reduces retrieval of phrases split between lines. when searching for the phrase
"sampled images", several instances are located, but not the one in
page 37.
In Batch Sequences
(BatchSequences.pdf), the title in the first page was converted to a bitmap --
making it impossible to locate; a similar problem is seen in ADBC.pdf. This problem,
where larger-size characters are transformed to bitmaps, is related to the
PostScript driver being used.
Additional
Examples
To see potential problems
with products that support advanced typography features, such as ligatures,
small caps and old-style numerals, see the Adobe OpenType User Guide,
authored with Adobe InDesign and exported directly to PDF:
·
"2002"
is present in the first page below the title -- but cannot be located as since
old-style figures are used.
- The SFNT acronym present in the first paragraph in
page 2 cannot be located, as it uses small-caps.
- "Microsoft" is present 5 times in this
document -- but none of the instances can be located due to the use of
ligatures (ft in this case). Even the word "This" in the opening
paragraph in page 2 (line before last) cannot be located due to the use of
ligatures. The more common fi, fl, ffi ligatures are searchable in the
case of this document, but this is not the case in other documents using
these ligatures (this depends on the applications used to author/create
the PDF).
While these OpenType
features result in a superior typography, they should be avoided in online
documents, until Acrobat Find and Search functions are enhanced to support the
additional characters.
As an example for a PDF
with text that is internally deformed, see the Adobe InDesign Programming Guide.
It includes numerous code fragments (see pages 419 and onwards) set in a
monospace font, and the same font is used in regular text to indicate function
names or related items. All of these are not searchable. Copy and paste the
text and you'll see why: "matrix passed" is understood internally as
"2#___A".#%%_&"". With this type of document, users
could have happily used the copy and paste function to reduce typing
time/errors when studying or implementing the techniques discussed, but results
in this case are of no value.